@喻快等:《基于强化学习的古今汉语句子对齐研究》
摘要
在传统双语平行语料的句子对齐研究中,传统方法根据双语文本中的长度、词汇、共现文字等特征信息建立综合评判标准来衡量两个句对的相似度。此类方法对句子语义匹配的能力有限,并且在多对多的对齐模式上表现不佳。
该文利用具有强大语义能力的预训练语言模型,并基于动态规划算法的强化学习训练目标来整合段落全局信息,进行无监督训练。实验结果证明,使用该方法训练得到的模型性能优于此前获得最好表现的基线模型,特别是在多对多对齐模式下,性能提升显著。
- 预训练语言模型 (PLM):利用PLM强大的语义能力进行句子编码和语义匹配,例如BERT。
- 动态规划 (DP):整合段落全局信息,以覆盖尽量多的平行句对为目标,寻找最优对齐结果。
- 强化学习 (RL):以动态规划的全局信息作为指导,通过奖励机制优化模型,提升多对多对齐的匹配能力。
1. 背景
- 基于深度学习的有监督机器翻译效果良好,但依赖大量高质量的对齐语料。
- 古今翻译场景下,高质量平行语料相对匮乏,语料对齐具有重要研究价值。
- 传统句子对齐方法依赖人工提取特征,对句子语义匹配能力有限,且在多对多的对齐模式上表现不佳。
2. 任务和数据
- 数据集
- 《二十四史》,包含300篇古今汉语文章,人工标注1550句对作为测试集。
- 获取粗对齐平行句对
- 将已有的手工对齐的古汉文与现代文的段落对作为输入,使用LCS算法来进行段落内部的句子的对齐,构建粗粒度的句对齐的平行语料
- 使用负采样方法构建训练语料。首先获取包含n个平行句对的平行语料库作为正例,为了构建负例,对于每一个平行句对,在语料库里面进行随机采样,构建新的句对生成m个负例
3. 详细方法
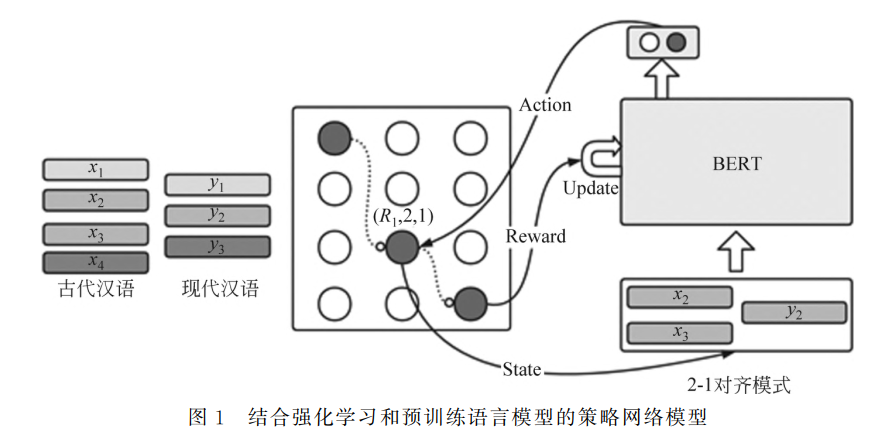
基于预训练语言模型的语义匹配模块
- 将古文和现代文文本分别记为
和 :
x^{(2)} = x^{(2)}_1 + x^{(2)}_2 + ... + x^{(2)}_m
X = \text{[CLS]} \ x^{(1)}_1 \ x^{(1)}_2 \ ... \ x^{(1)}_n \ \text{[SEP]} \ x^{(2)}_1 \ x^{(2)}_2 \ ... \ x^{(2)}_n \ \text{[SEP]}
$$
- BERT编码:
- Reward设定:
(不匹配): Reward = 0 (匹配): - 1-1对齐: Reward = 2
- 1-2, 2-1, 2-2对齐: Reward = 3
补充伪标注生成过程
假设古文段落有 3 句(A-B-C),现代文段落有 4 句(1-2-3-4),目标是找到所有句子的对应关系。
真实标注(理想情况)
A ↔ 1
B ↔ 2
C ↔ 3-4(1-2对齐模式)
伪标注生成过程
-
动态规划初始化
- 构建得分矩阵
D[i][j],表示古文前 i 句和现代文前 j 句的最佳对齐得分。 - 初始化:
D[0][0] = 0(起点)。
- 构建得分矩阵
-
逐句匹配得分计算
- 对每个位置
(i,j),计算四种可能对齐方式的得分:- 1-1 对齐:
D[i-1][j-1] + 语义匹配分(Ai, Bj) - 1-2 对齐:
D[i-1][j-2] + 语义匹配分(Ai, Bj-1+Bj) - 2-1 对齐:
D[i-2][j-1] + 语义匹配分(Ai-1+Ai, Bj) - 2-2 对齐:
D[i-2][j-2] + 语义匹配分(Ai-1+Ai, Bj-1+Bj)
- 1-1 对齐:
- 语义匹配分由预训练模型(如 BERT)给出,例如:
BERT("A", "1") → 0.9 BERT("B", "2") → 0.8 BERT("C", "3-4") → 0.7
- 对每个位置
-
选择最优路径
- 动态规划矩阵逐步填充,最终得到全局最优路径:
A-1 → B-2 → C-3-4 总得分 = 0.9 + 0.8 + 0.7 = 2.4 - 伪标注生成:将路径中的对齐关系(A-1, B-2, C-3-4)作为伪标签。
- 动态规划矩阵逐步填充,最终得到全局最优路径:
-
加上奖励
假设古文段落为A-B,现代文段落为1-2-3:
动态规划路径选择:
- 路径1:
A-1(1-1)→B-2-3(1-2)- 若BERT判断
A-1匹配(概率0.9),奖励+2;B-2-3匹配(概率0.8),奖励+3。 - 总奖励:
2 + 3 = 5
- 若BERT判断
- 路径2:
A-B(2-2)→1-2-3(2-3,超出范围)- 若BERT判断
A-B-1-2匹配失败,奖励为0。
结果:动态规划选择路径1,奖励更高且覆盖更多句子。
- 若BERT判断
策略梯度训练
- 策略网络BERT 接收到当前对齐模式状态
, 输出动作 , 接着环境把 当成输入, 构成新的状态 作为输入, 进而输出决策 。
- BERT 会不断地接收到动态规划过程中所采集到的状态, 并且根据模型内部的参数
而进行决策(Action), 进而得到一系列的观测序列 , 动态规划完毕后即为完成一次完整的观测序列, 每一次完整的观测可以视为一个轨迹 。 - 轨迹就是当前的输入的对齐模式的句对、采取的策略, 根据
执行 的概率 ) 是由 模型的参数 决定, 该输出是一个分布, BERT 会根据这个分布进行采样, 决定实际要采取的动作。 - 接下来环境根据动作
与 产生 计算, 以此类推, 某个完整轨迹 发生的概率如式(7)所示。
- 把环境输出的状态
与BERT 输出的动作 组合起来, 并且将动态规划过程中每一步的 Reward累加起来作为当前回合的总 Reward, 就得到了 ,我们的目标就是调整BERT 模型参数 , 最大化 的期望值 )。 - 在决策过程, 需要尽可能穷举每一个轨迹
, 从分布 )采样一个轨迹 , 计算 )的期望值, 并且计算期望 的梯度如式(8)所示。
- 计算某一个状态下某一个动作的对数概率
), 对这个概率取梯度, 在梯度前面乘一个权重, 权重就是当前采样轨迹的奖励, 计算出梯度后, 就可以更新模型, 梯度计算:
- 使用梯度上升 (Gradient Ascent) 的方式来更新参数
, 来最大化期望奖励, 把 加上梯度 , 学习率设置为 , 学习率的调整可以使用 优化器来调整。
策略网络初始化
- 我们从先前手工段对齐语料中抽取300 段语料, 使用 LCS 算法构建伪平行语料对 BERT-base进行微调后得到的模型, 作为本次实验的基线模型, 并在此基础上进行强化学习训练。
- 在强化学习的训练过程中, 采样轨迹
得到 ) 一直是正的, 由于只采样了部分的动作序列, 某时刻的动作可能从来没被采样到, 导致该动作在策略网络的执行概率会降低, 但这并不意味着未被采样到的动作不是好的决策, 为了让采样得到的 有正负之分, 可以添加基线 , 使得总奖励为 , 如果 , 就让当前状态的动作发生的概率升高, 反之亦然。 - 通过使用这种带基线的策略梯度算法, 提升了训练过程的稳定性, 梯度计算如:
- 在强化学习训练过程中,
设置为基线模型根据输入的段落对齐文本在经过动态规划判断完毕所获得的总reward, reward函数同上3.2.2节目标的设定所述。
4. 实验
- 评价指标:精确率 (Precision), 召回率 (Recall), F1-score。
- 假设 GB 是人工标注的数据集,PB是模型产生的集合, 召回率和精确率的计算如式(12)所示。
- 基线模型:
- 基于长度的对齐方法 (Length)
- 基于综合特征的对齐方法 (Statistical)
- 基于LCS的对齐方法 (LCS)
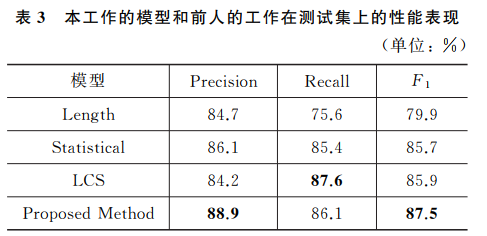
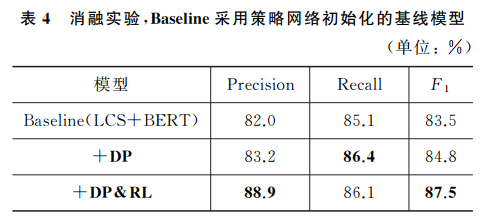
5. 结果
- 本文提出的方法 (Proposed Method) 在Precision和F1-score上均优于基线模型。
- 消融实验表明,动态规划和强化学习均能提升对齐性能。
- 在多对多对齐模式下,本文方法准确率显著提升。
6. 结论
本文提出的基于预训练语言模型和强化学习的古今汉语句子对齐方法,能够有效提升对齐性能,特别是在多对多对齐模式下。该方法为解决古今翻译场景下平行语料匮乏问题提供了一种新的思路。